- Published on
The Key to Automating Testing for Database Logic Bugs - Test Oracle
- Authors

- Name
- Bryce Yu
- @earayu
概述
数据库系统作为现如今大多数应用的核心,承载着数据的存取以及部分计算任务。数据库作为底层基础设施,大家普遍期望它是充分测试并可靠的。但是就跟任何一个复杂的大型软件一样,数据库也无可避免地会存在bug。而其中最危险也最让人难以捉摸的,莫过于逻辑bug了。逻辑bug,即数据库返回了错误结果。 科学的方法论以及工程化的手段是保障数据库质量的重要方式。本文重点探讨的是如何自动化测试数据库的逻辑bug。
致命的逻辑bug
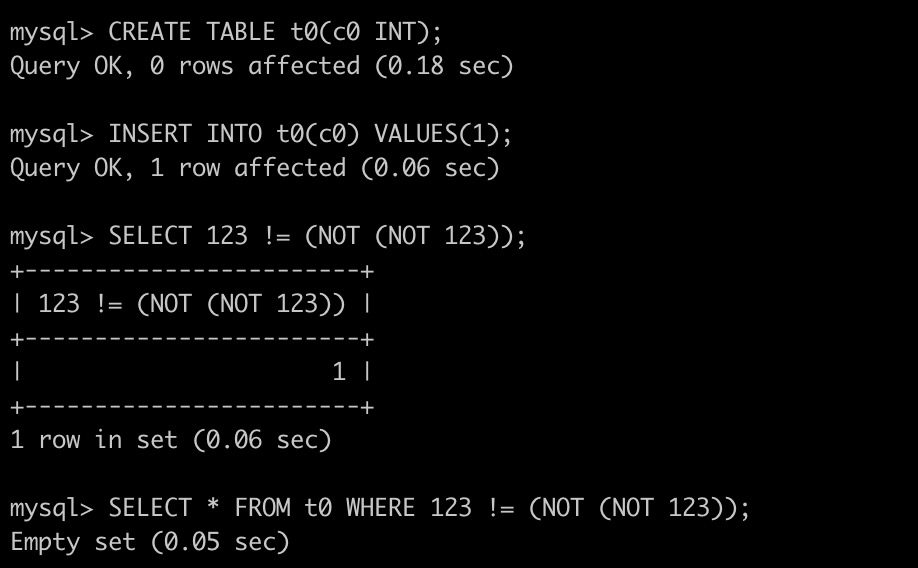 像这样返回错误结果的逻辑bug,很可能造成业务数据不一致。如果配合上Delete语句,甚至有可能造成所有业务数据的丢失,是非常危险的一类bug。
像这样返回错误结果的逻辑bug,很可能造成业务数据不一致。如果配合上Delete语句,甚至有可能造成所有业务数据的丢失,是非常危险的一类bug。自动化测试的关键
逻辑bug的危险性还在于它的隐蔽性。有时候甚至需要非常复杂的表达式才能触发,又有时候相同表达式在SQL语句的不同位置计算的结果不同。所以固化的用例和手工的测试很难以有效地发现问题,那么,难道只能让用户作为那个第一个吃螃蟹的人了吗?当然不是,我们只要能够引入有效的随机化全自动测试,就能高效地发现这些逻辑bug。 但是,数据库领域的随机全自动逻辑bug测试,之前鲜有相关的研究,因为之前一直都缺位了一个理论:如何判断一条SQL语句的执行结果是正确还是失败?直到Manuel Rigger博士发表了他那3篇数据库测试论文。
数据库领域的Test Oracles
在测试理论中,Test Oracle是一种用于判断测试用例是否执行成功的机制。最简单的Test Oracle可以是单元测试中的assert语句,其他数据库也可以作为Test Oracle。
Differential Testing
可以把相同的SQL发送给2个不同的数据库各自执行,如果结果不一致,则很有可能其中一个存在bug。这种方式被称之为Differential Testing。但是它的缺点也很明显:首先,它不满足测试理论中的Completeness和Soundness。比如,如果2个数据库存在相同的逻辑bug,它是检测不出来的。其次,虽然很早之前就出现过SQL标准,但不同的数据库仍有它们各自的SQL方言,并且在标准不明确的地方不同的数据库也有各自不同的实现。这些缺点都造成了Differential Testing测试范围的狭小以及效果不够理想。 下面,介绍3种Manuel Rigger博士提出的能够探测数据库逻辑bug的Test Oracles。
Pivoted Query Synthesis
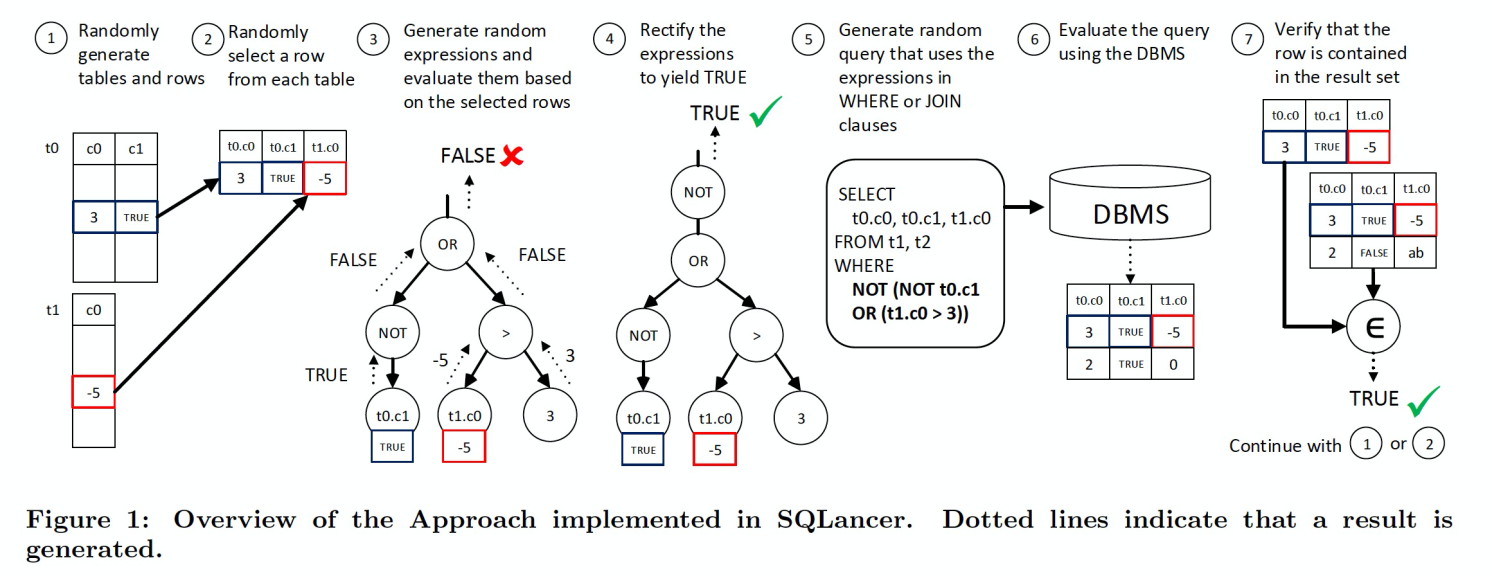
Pivoted Query Synthesis(后简称PQS)的核心原理是:对于一行数据(称之为pivot row),会生成很多条SQL并且确保这些SQL从语义上一定能查询到这行数据,如果实际执行时发现没有查询到这条数据,则很可能是有bug存在。具体流程如下:
- 随机生成一些tables和rows,确保每张表都至少有一行数据
- 从每张表中随机选择一行数据,它们被称之为pivot row
- 根据pivot row中存在的列以及对应的值,随机生成结果为TRUE或者FALSE表达式
- 调整表达式,使它返回TRUE
- 生成select语句,并把刚才随机生成的表达式用在where/join语句中
- 执行select语句
- 验证pivot row在结果集中,如果不在,则说明找到了一个bug
- 以上是一轮测试。下一轮可以从第1步或第2步开始
Non-Optimizing Reference Engine Construction
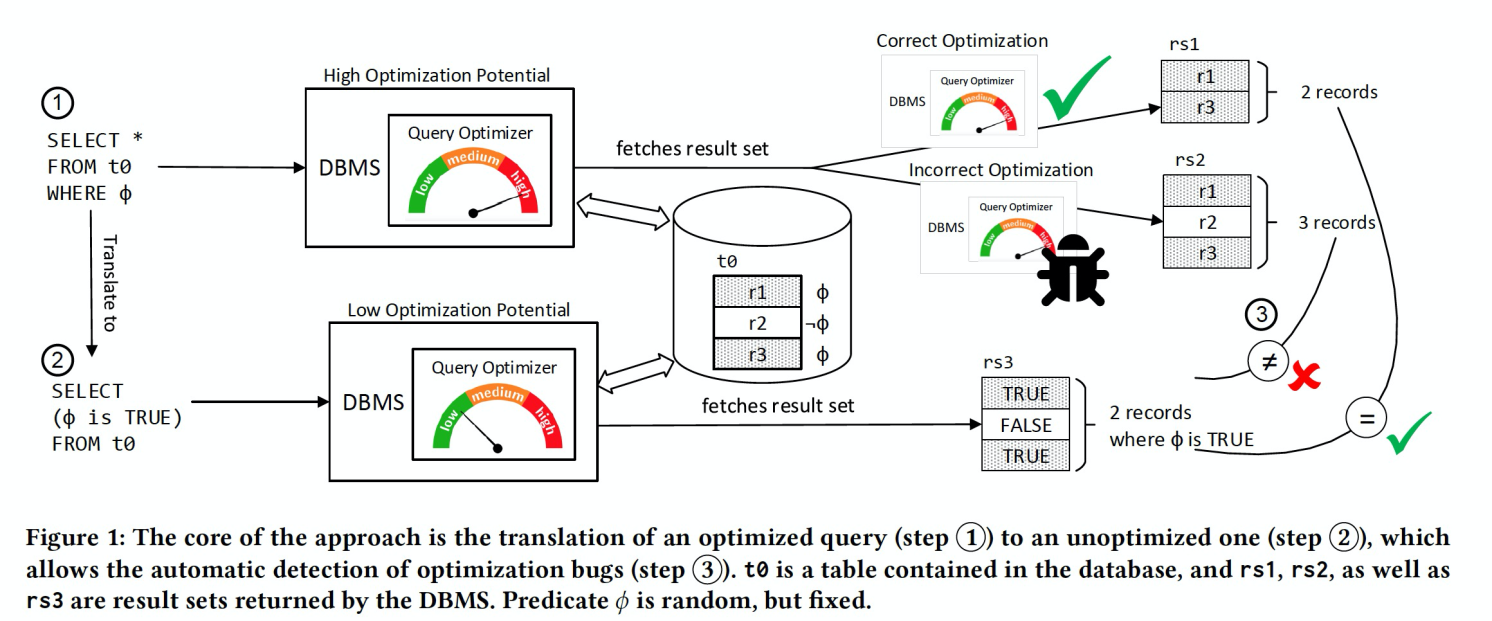
Non-Optimizing Reference Engine Construction(后简称NoREC)的核心原理是:生成2条SQL,其中一条容易被优化器优化,另一条难以被优化器优化。然后比较2条SQL的查询结果,如果不同,则证明优化器可能存在bug。具体流程如下:
- 随机生成一些数据库/表/数据
- 随机生成一条查询SQL语句,记为: select * from t0 where $expr
- 执行这条SQL,返回的结果集为RS
- 将这条SQL转换成这样的形似:select $expr is TRUE from t0。记为SQL'
- 执行SQL'。返回的结果集为RS'
- 比较RS和RS'中数据条目的数量,如果不同,则很可能发现了一个bug
Ternary Query Partitioning
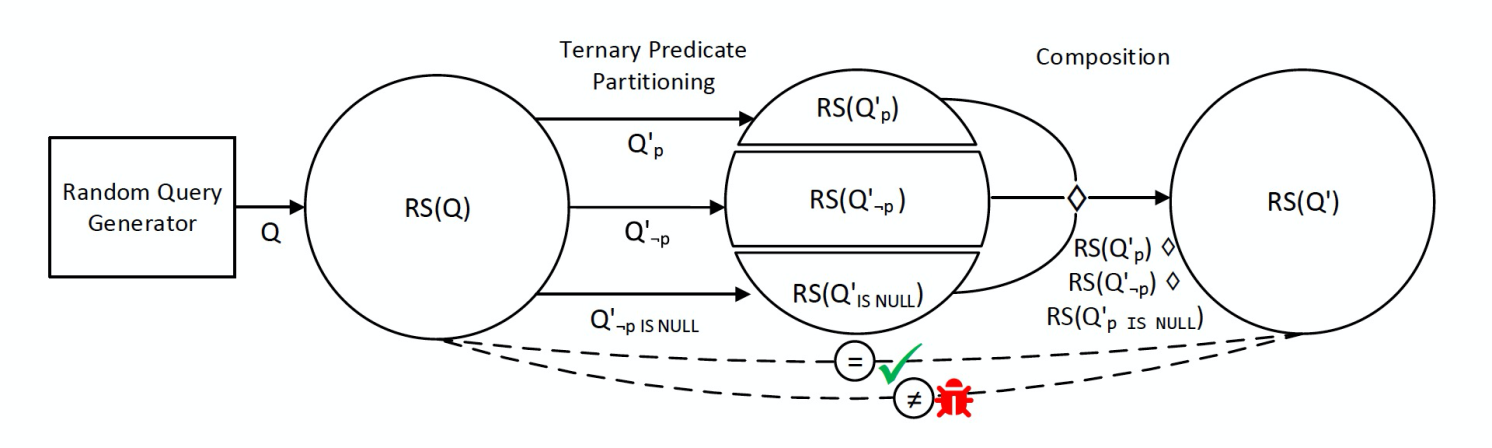
Ternary Query Partitioning(后简称TLP)的核心原理是:将一条查询SQL语句,分化成多条SQL语句,从语义上保证分化出来的多条SQL语句的结果集应该等于原始SQL语句。让数据库执行它们,如果它们的结果集不同,则很可能找到了一个逻辑bug。下面是具体流程:
- 生成一个数据库,包含一些表,以及一些数据
- 随机生成一条查询SQL,称之为Q。查询结果指代为RS(Q)
- 分化成3条查询SQL,称之为Q'(p)、Q'(not p)、Q'(p is null)。查询结果指代为RS(Q'(p))、RS(Q'(not p))、RS(Q'(p is null))
- 根据Q类型的不同,使用特定的表达式将Q'的3个结果集组合起来,指代为RS(Q')
- 判断,RS(Q)==RS(Q')。如果不相等,则很可能遇到了一个逻辑bug
总结
Manuel Rigger博士通过以上3种方式测试了市面上广为流行的几个数据库,如SqLite、MySQL、PostgreSQL等,一共找到了450多个bug,其中近一般是数据库的逻辑bug。从实现成本来看,PQS要求实现各个算子的计算逻辑,所以成本较高;NoREC和TLP的实现成本较低。从测试范围来看,TLP可以测试Where、Group By、Having、Distinct、Aggregate函数等场景;PQS和NoREC测试的场景范围较窄。 数据库的逻辑bug不同于执行异常,它会返回错误的结果,从而对上层应用程度埋下了重大的业务安全隐患。我们会一以贯之地通过理论与工程的结合,持续提升PolarDB-X的技术质量。
参考资料
- The Oracle Problem in Software Testing: A Survey
- Testing Database Engines via Pivoted Query Synthesis
- Finding Bugs in Database Systems via Query Partitioning
- Detecting Optimization Bugs in Database Engines via Non-Optimizing Reference Engine Construction
- Metamorphic Testing: A Review of Challenges and Opportunities